Le New York Times a fait réaliser une intéressante étude par Comscore sur le nombre de données récoltées sur le comportement des internautes par différentes compagnies. Le tout est résumé dans le tableau ci-dessous.
Story Louise, To Aim Ads, Web Is Keeping Closer Eye on You, New-York Times, 10 Mars 2008. Html
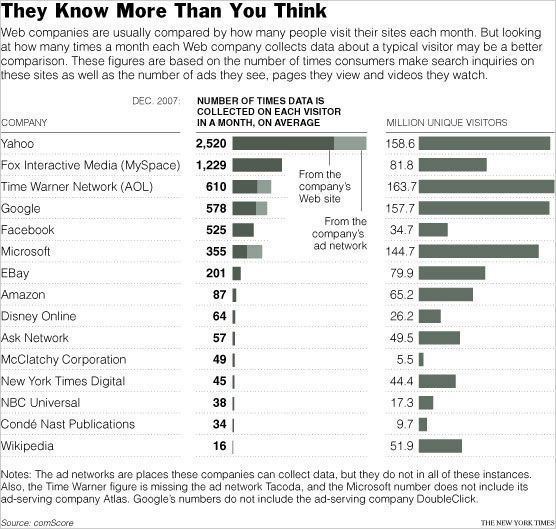
La majorité des commentateurs et un certain nombre de politiques des deux côtés de l'Atlantique s'inquiètent de cette récolte de données pour la protection de la vie privée des internautes, face à des velléités de contrôles politique ou commercial. Sans minimiser ces risques et leur gravité ponctuelle, je pense que l'essentiel est ailleurs et que ces risques là relèvent plus d'une maladie infantile du média. Pour bien le comprendre, il est utile de comparer les pratiques des anciens médias et du nouveau.
La radio et la télévision s'intéressent depuis longtemps aux comportements des auditeurs et téléspectateurs. L'objectif est double : construire une grille de programmes permettant de réunir le plus grand nombre de personnes ; vendre l'attention captée à des annonceurs. Il est essentiel de constater que si ces deux objectifs sont évidemment liés, la liaison n'est pas bijective. Le second dépend du premier, mais le premier est indépendant du second. Une radio ou une télévision non-commerciale doit néanmoins réunir un auditoire et s'intéresser donc au comportement de celui-ci. Et, par ailleurs, les annonceurs, clients des médias, sont friands de données fines sur les comportements, réalisés par des consultants de marketing, données qui sont d'une importance secondaire pour les programmateurs. Les principaux acteurs du Web-média s'intéressent au comportement des internautes pour les deux mêmes raisons : pour améliorer l'efficacité de leurs outils (voir ici) et pour vendre de l'attention aux annonceurs. De la même façon, la relation entre les deux objectifs n'est pas bijective et bien éloignée d'un souci de contrôle des comportements. La différence avec les médias traditionnels vient du fait que le Web-média a accès directement à des données comportementales et peut être tenté de s'en servir comme un consultant de marketing. C'est le jeu que Facebook a essayé de jouer. Je ne suis pas sûr qu'il ne soit pas voué à l'échec, car en cette matière quand l'observateur est en même temps acteur, il fausse le jeu.
Mais, extrait de l'article du NYT (trad JMS) : Les principaux réseaux de télévision et firmes de presse «ne sont même pas dans dans la même catégorie» a déclaré Linda Abraham, une des vice-présidentes exécutives de Comscore. «Ils ne peuvent réellement jouer sur ce terrain». Les chiffres sont frappants, les médias anciens ne recueillent pas directement les données comportementales. Il y a deux raisons. La première tient au fait qu'il s'agit de médias de diffusion et non d'accès (voir là) et qu'en passant sur le Web ils n'ont pas encore vraiment changé leur tradition. Les médias d'accès sont, par nature, calés sur le comportement de leurs lecteurs puisque leur vocation est d'accompagner et faciliter leurs actions.
La seconde raison est aussi d'importance. Les données, pour les médias traditionnels, ne sont pas recueillies par le média lui-même, mais par un tiers de confiance (Médiamétrie en France, Nielson aux US). C'est ce tiers qui fournit l'étalon permettant la réalisation d'un prix de marché des annonces. Cet étage là n'existe pas, pas encore, dans le Web-média, même si des firmes justement comme Comscore ambitionnent de prendre cette place. Compte-tenu de la spécificité du Web-média, il n'est pas sûr que ces données puissent être partagées. Mais alors on peut se demander si le Web-média peut dépasser une structure oligopolistique ou si un prix de marché peut s'y construire raisonnablement.
Repéré par un article du Monde, qui commente celui du NYT ici.
Actu 17 mars 2008 Voir aussi ce vieux billet : Comment Google collecte vos données personnelles : cartographie des services Google, Par Youri REGNIER, vendredi 8 juin 2007 ici