Roger et la trahison de Google Books
Par Jean-Michel Salaun le mardi 14 août 2007, 02:38 - Sémio - Lien permanent
Inheritance and loss? A brief survey of Google Books by Paul Duguid First Monday, volume 12, number 8 (August 2007). Html
Un article sur la qualité de la numérisation de livres chez Google qui mérite attention, non pour ses constatations : la qualité est mauvaise, c'est bien connu et documenté, mais pour la conclusion. Extrait (trad JMS) :
Le Google Books Project est surement un programme important, sur plus d'un point même inestimable. C'est aussi, comme la preuve en a été brièvement administrée ici, un programme hautement problématique. Comptant sur la puissance de ses outils de recherche, Google a négligé des métadonnées élémentaires, comme le numéro de volume. La qualité de la numérisation (et donc on peut supposer celle de la recherche) est parfois totalement inadéquate. Les éditions proposées (à la recherche ou à la vente) sont, au mieux, regrettables. Étonnamment, cela me laisse penser que les techniciens de Google ont une vision plus romantique du livre que les bibliothécaires. Google Books considèrent les livres comme un entrepôt de sagesse à exploiter avec de nouveaux outils. Ils ne voient pas ce que les bibliothécaires savent : Les livres peuvent être des choses obtuses, obstinés et même odieuses. En général, ils ne se résignent pas à entrer sur une étagère standardisée, un scanner standardisé ou une ontologie standardisée. On ne peut non plus surmonter leurs contraintes en grattant le texte ou en développant des algorithmes. Sans doute ces stratégies sont utiles, mais en essayant de laisser de côté des contraintes vraiment simples (comme les volumes) ces stratégies sous-estiment le fait que les rigidités des livres sont en même temps des ressources qui précisent comment les auteurs et les éditeurs ont cherché à créer le contenu, le sens et la signification que Google cherche aujourd'hui à libérer. Même avec les meilleures technologies de recherche et de numérisation à sa disposition, il est imprudent d'ignorer les éléments livresque d'un livre. D'une façon plus générale, un transfert des artéfacts de communication complexes entre les générations de technologies est sûrement problématique et non automatique.
Finalement, considérant la transmission comme une assurance qualité, la question de la qualité dans le programme bibliothèque de Google Book nous rappelle que les formes nouvelles sont toujours susceptibles de parricide, détruisant dans le processus les ressources dont elles espèrent hériter. Cela reste problématique, par exemple, pour Google News. Dans leur offre gratuite d'actualités, cela risque de miner le flot entrant des sources sur la qualité desquelles Google News compte pour vivre. Cela est aussi vrai, à une moindre mesure, pour Google Books. Google compte ici sur l'assurance qualité des grandes bibliothèques qui collaborent au projet. Les bibliothèques de Harvard et de Standford ne voient pas leur réputation renforcées par la qualité douteuse de Tristram Shandy (note JMS :livre ayant servi à la démonstration de l'auteur), marquée à leur nom dans la base de données de Google. Et Tristram Shandy n'est pas le seul. Pour chaque page mal numérisée ou chaque livre mal catalogué, Google ternit non seulement sa propre réputation sur la qualité et la sophistication de sa technologie, mais aussi celle des institutions qui se sont alliées avec lui.(..)
Voilà des affirmations qui alimenteront sûrement les débats entre partisans et adversaires du projet.
Actu du 10-09-2008
Un des débats les plus intéressants a eu lieu sur le liste des historiens du livre SHARP-L entre P. Duguid et P. Leary, auteur de l'article Googling the Victorians (pdf) qui montre a contrario combien l'outil est utile pour les historiens. Le débat a été reproduit par P. Brandley dans un billet sur O'Reilly Radar sous le titre The Google exchange.
Mon intérêt est ailleurs, sur le fond de la question posée qui rappelle les réflexions de Roger et prennent ici une dimension économique que je n'avais pas encore perçue.
Le premier texte de Roger a fait ressortir trois dimensions indissociables pour définir un document que je traduirais aujourd'hui ainsi :
- Anthropologique : Forme (Document = Support + Inscription)
- Intellectuelle :Texte (Document = Code + représentation)
- Sociale : Médium (Document = Mémoire + transaction)
ou sous forme d'un schéma :
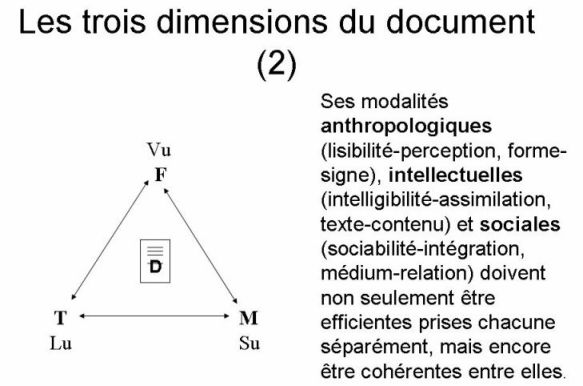
La remarque de P. Duguid revient à dire que la transposition par Google d'un livre sous format numérique n'a pris en compte (et mal) que la dimension du texte, en s'appuyant sur sa valeur sociale construite par les bibliothèques et en oubliant la forme. On pourrait dire aussi qu'un livre ancien et prenant une valeur patrimoniale réduit l'importance du texte au profit de la forme ce qu'a oublié Google, spécialiste du traitement linguistique.
Une autre facette du problème est soulevée par l'auteur celui de la fidélité de la transposition qui pose la question de la très difficile définition du texte. Celle-ci est traité cette fois dans le deuxième texte de Roger, qui se demande notamment comment définir les invariants documentaires à préserver dans une transposition de forme.
Le plus intéressant donc, pour moi, dans l'article de P. Duguid est de constater que les réflexions de Roger trouvent ici un écho pratique doublé enjeu économique. Ces difficultés ont, en effet d'après l'auteur, des conséquences sur la valeur de l'objet créé et en retour sur celle de la source.
Commentaires
D'abord merci Jean-Michel pour ce signalement et pour ta traduction. Sans pouvoir me plonger dans le texte d'origine (je ne nage bien que dans ma langue maternelle) quelques remarques en passant sur les aspects fort intéressants pointés ici.
D'abord, calmons-nous un peu sur Google Print ;-) Ok pour chercher les poux dans la tête de ce fabuleux projet, histoire d'aiguiser notre esprit critique mais rendons à Jules ce qui est à César. À ma connaissance, ce ne sont pas les 'techniciens de Google' qui sont responsables du choix 'regrettable' des ouvrages numérisés mais les bibliothèques partenaires du programme... Qu'en disent-elles ?
Ensuite, le numérisation implique, par définition, une transposition de forme. Une transition de forme, dirai-je. Donc à mes yeux, il va de soi que le support d'origine, l'exemplaire servant de matrice à la numérisation, ne peut être intégralement restitué dans cette transposition de forme. On peut sans doute le regretter. Et de ce point de vue, le numéro des volumes n'est sans doute pas le seul caractère matériel du livre à disparaître -- à s'effacer plutôt : en dehors des métadonnées, ce numéro est récupérable sur les facsimilés. Au delà des dimensions de l'imprimé, on aimerait connaître le poids du volume, son épaisseur, etc. Toutes choses que Google n'est pas le seul à oublier... Y a-t-il beaucoup de bases de données bibliographiques qui reflèteraient une image complète et fidèle de l'exemplaire d'origine ? C'est tout simplement impossible selon moi. Si la numérisation oublie (au moins) la moitié du monde réel, loin d'être un défaut, c'est la condition même de son existence et de son efficacité. Un peu comme un plan ou une coupe dans le dessin d'architecture : abstraire une partie des données pour faciliter l'accès et la compréhension du reste. Ainsi le plan, la coupe, la perspective, ... la numérisation.
Il y a enfin autre chose que révèle, en creux, ce texte. C'est la prodigieuse efficacité du mode facsimilé. On est bien loin du débat quasi-théologiques entre mode 'image' et mode caractère qui fait rage aux prémisses de la numérisation de Gallica, par exemple. Le mode 'image' et le mode caractère se consolident mutuellement dans la transition de forme qu'est la numérisation. Le premier reflète au mieux la matérialité du livre (dans un état de la technique donnée) et sans le mode caractère (probabiliste et même truffé d'erreurs !) le mode 'image' serait tout simplement inaccessible. La fin (passée inaperçue) de cette querelle me semble remarquable.
Pierre
Pour rebondir sur la remarque de Pierre, à propos de l'extinction de la querelle entre le mode image et le mode caractère, si je suis d'accord avec lui pour penser que dans le domaine des fonds bibliothéconomiques, elle est quasiment éteinte, dans le domaine du documentaire contemporain elle garde toute sa valeur, et les observations de Roger à ce propos restent pertinentes.
Notre hôpital, qui a passé du microfilmage à la numérisation de dossiers actifs ou semi-actifs a connu cette discussion, lorsque nos informaticiens (universitaires et chercheurs dans l'analyse du texte en language naturel) ont commencés par refuser une numérisation en mode image car créant des documents non "exploitables".
Le compromis actuel est que les documents sont stockés en trois modalités, qui correspondent à trois usages différents:
- Une image tif, qui représente l'image originale et qui est conservée à des fins d'archivage
- un document "océrisé" au format pdf pour la consultation par les personnes autorisées de l'établissement
- un document XML pour l'exploitation par les applications informatiques
Cela renvoie à une problématique plus large, pas encore résolue, qui est celle de la "documentarisation" ou "redocumentarisation" (voir les publications d'O. Zacklad). En l'état de ma réflexion je la poserais en ces termes: cherche-t-on à conserver/accéder à une (des) donnée(s) ou à un(des) document(s), ou les deux ? La plupart de nos activités actuelles sont un compromis entre ces trois options sans qu'elles soient explicitement distinguées. La réflexion de Roger peut nous aider à choisir le document lorsque cela est nécessaire. Cela commence à devenir clair dans nos milieux professionnels, cela est encore très confus dans le grand public et chez nos décideurs (voire les errement de la cyberadministration un peu partout dans le monde).
Je cite :
"La réflexion de Roger peut nous aider à choisir le document lorsque cela est nécessaire. Cela commence à devenir clair dans nos milieux professionnels, [...]"
Mon milieu professionnel est, comme vous, celui de la médecine (Informatique médicale hospitalière pour être précis) et je me permets de penser que ce n'est pas si clair que cela : Dans bien des choix informatiques, l'intérêt du document en tant que tel n'est pas compris et l'échec d'applications informatiques hospitalières uniquement centrées sur des données n'est toujours pas analysé. Alors que de nombreux articles de recherche dans les domaines informatiques ou SHS ont pointé ces problèmes depuis un certain nombre d'années déjà (par exemple les articles de Tange ou M. Berg dans Medline).
J'ai bien dit "commence" à devenir clair, et pour moi le milieu professionnel cité est plutôt celui de l'info-doc/archives que le milieu médical proprement dit. Je prépare un article dont les conclusions développent un peu plus sur ce sujet et je le signalerai dès qu'il sera paru. Dans ce contexte, les liens sur les articles de Tange et de Berg que vous citez me seraient des plus utiles.
Il y a dans la bibliographie de mon mémoire d'HDR
tel.archives-ouvertes.fr/...
les références des 2 articles de Berg et Tange.
Il y a dans la bibliographie de la thèse de Sandra Bringay, une autre référence de Berg et, surtout, un travail sur la justification des documents et des annotations pour le dossier médical
tel.archives-ouvertes.fr/...
Je peux aussi vous envoyer directement 1 ou 2 articles de Marc Berg.