Économies de Wikipédia : 2. l'attention
Par Jean-Michel Salaun le dimanche 08 avril 2007, 06:26 - Web 2.0 - Lien permanent
Pour analyser lucidement l'économie de Wikipédia, il est prudent d'en distinguer trois dimensions. Dans ce billet, j'aborde l'une d'entre elles : l'économie de l'attention. Les deux autres sont analysées dans deux billets indépendants. Celui-ci n'épuise donc pas la question, il n'en effleure qu'un seul volet.
L'économie de l'attention, dont l'objectif est de pouvoir modifier à son profit les comportements de consommation, comprend deux séquences interdépendantes : la capacité de capter l'attention du consommateur potentiel, comme pour la publicité commerciale dans les médias ; la capacité de reconnaitre les comportements des consommateurs, traditionnellement dévolue aux enquêtes marketing. Sur chacun, le Web apporte des innovations radicales (voir ici et là). La première a été renouvelée par les moteurs, l'attention étant captée et vendue au moment de la recherche d'information et non plus seulement au moment de la lecture. Pour la seconde, la tracabilité exceptionnelle de l'internet autorise une connaissance des comportements au moins aussi fine que celle des sondages et qui peut s'articuler directement avec l'achat, le Web pouvant être une place de marché. La bataille commerciale du Web, concentrée aujourd'hui sur le Web 2.0, se porte sur ces deux séquences. Pour le moment, un nombre très réduit d'acteurs tire son épingle du jeu, raflant la majorité des revenus. Le plus important d'entre eux est, bien entendu, Google.
Wikipédia, intervenant dans le domaine du savoir, est moins concerné par la seconde séquence. Mais, comme nous allons le voir, se trouve au coeur de la première, alors même qu'il ne participe pas à ses transactions.
Chaque fois qu'un service réussit à attirer un nombre important d'internautes. Il se positionne de fait dans l'économie de l'attention, il s'articule avec d'autres, il crée de la valeur potentielle. Mais il peut aussi détourner à son profit de la valeur crée par d'autres, car l'attention humaine étant limitée son marché agit comme un système de vases communicants, l'attention captée par les uns l'est au détriment de celle captée par les autres. S'il n'est déjà sous contrôle d'une des firmes dominantes, il devient une proie convoitée.
J'ai déjà donné les chiffres sur le succès de Wikipédia auprès des internautes. Le graphique ci-dessous, tiré d'un billet de Hitwise montre l'origine des interrogations sur Wikipédia.
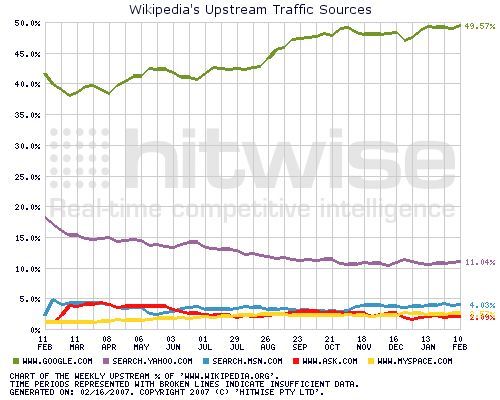
Sans grande surprise, on y retrouve la struture de la recherche sur le Web avec la domination de Google. Mais, le succès explosif de Wikipédia auprès des internautes fait, apprend-on dans le même billet, que l'augmentation de la part de Wikipédia dans le traffic généré par Google a augmenté de 166% (de février 2006 à février 2007) pour atteindre 1,87%. Dit autrement de façon un peu schématique, Wikipédia entre pour un peu moins de 2% dans la création de la valeur d'attention créée par Google. John Battelle a sans doute exprimé le plus brutalement la tension créée par ce succès.
Regardless of posturing, no business likes to send that much traffic to a third party site without some kind of value coming back. Will Wikipedia start running AdWords? Watch this space. I could imagine some kind of approach that drives revenue to the Wikimedia foundation....
Maintenant, si l'on s'intéresse à l'autre versant du traffic, c'est à dire où vont les internautes après avoir consulté Wikipédia, un nouveau billet de Hitwise, consacré au traffic du Royaume-Uni, nous apprend qu'ils se dirigent principalement vers les sites du secteur de l'informatique et de l'internet.
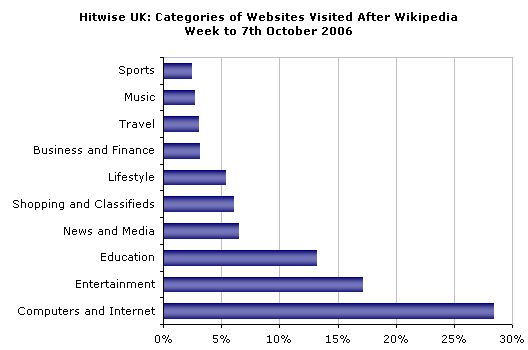
Je cite le billet : The Computers and Internet category is the largest downstream category from Wikipedia, as it includes Search Engines and Net Communities and Chat. Search Engines is an example of a category where there is a clear authority - and that is Google. Nous retrouvons ainsi dans les deux sens du traffic l'articulation avec les mêmes joueurs.
On peut ajouter que Google et Wikipédia ont des vocations sinon similaires, tout du moins comparables ou complémentaires, comme en témoigne leur site respectif. Le moteur proclame : Google a pour mission d'organiser à l'échelle mondiale les informations dans le but de les rendre accessibles et utiles à tous, tandis que l'encyclopédie souligne : Ce projet est décrit par son cofondateur Jimmy Wales comme « un effort pour créer et distribuer une encyclopédie libre de la meilleure qualité possible à chaque personne sur la terre dans sa langue maternelle ».
Cette parentée explique sans doute, de façon très concrète, la résonnance qui s'est installée entre les deux services. D. Durand, en prenant l'exemple des blogues, propose l'illustration suivante qui mériterait sans doute une base chiffrée mais est stimulante :
- La blogosphère et la communauté du Web 2.0, toutes 2 en croissance exponentielle, génèrent de mois en mois un nombre de liens toujours plus colossaux vers les pages de Wikipedia. Le Pagerank de ces pages montent en proportion et les amène dorénavant en 1ère page des résultats des résultats organiques de Google: faites l'essai avec un ensemble de noms communs sur Google.com. C'est frappant! Avec Google.fr, cela commence aussi à émerger. Et ensuite, quand on est en 1ère page, on est cliqué d'où le trafic.
- Le pagerank de ces pages est ce qui se fait de mieux en termes de SEO ("Search Engine Optimizer", Optimiseur de moteur de recherche): il est élevé mais ne vient pas du "vote" de quelques autres pages elles-aussi élevées en termes de PageRank. Il vient plutôt d'une nuée de petites pages. Il est donc très "solide" face à la perte / disparition de certains des liens qui le composent!
De plus, les deux services raisonnent l'un et l'autre comme si le Web constituait un vaste texte. Le moteur calcule directement sur le texte des pages déjà publiées sur le Web, l'encyclopédie interdit dans ses principes la publication de travaux inédits. L'un et l'autre fondent leur existence sur le savoir publié, pour le traiter et le relier par des hyperliens. Néanmoins le raisonnement s'appuie sur des outils et des méthodes fondamentalement différentes. Le premier fait confiance à un algorithme, sans doute quelque peu manuellement redressé en fonction de l'expérience et peut-être d'intérêts particuliers. Le second s'appuie sur une communauté humaine, elle aussi sujette à des tentatives d'influence, qu'il faut encadrer. De façon un peu caricaturale, on pourrait dire un raisonnement de Web sémantique dans un cas versus un Web socio-sémantique (pour reprendre le terme de M. Zacklad) dans l'autre.
Reste à savoir si les deux logiques pourront s'articuler longtemps sans transaction financière. La dynamique collective de Wikipédia a, pour le moment, rendue tabou tout compromis en direction d'une rémunération issue du Web commercial. Les chiffres pourtant auront peut-être raison de ces réticences. Sans même parler du rachat de YouTube (1,6 Mds de USD) qui signifierait une perte d'autonomie sans doute fatale, je rappelle que Google a signé avec MySpace un contrat publicitaire sur trois années de 900 M de USD..
Ainsi notre billet sur l'économie de la cognition insistait sur l'articulation entre Wikipédia et le monde de l'éducation, celui-ci souligne l'appartenance à une autre sphère celle de l'économie de l'attention. Mais, dans l'un et l'autre cas, l'encyclopédie en ligne joue une partition à part, décalée par rapport aux orientations des autres acteurs,