Suite de l'analyse de la page de recherche de Google.
Rappel, dans un précédent billet (ici), j'ai analysé la partie haute de la page, selon le principe :
Chacun s'accorde à penser que le moteur de recherche, couplé à la publicité sur les réponses aux requêtes représente le cœur du métier de Google. Chacun aussi convient que la sobriété de la page de recherche a été un facteur déterminant dans son succès. Dès lors, l'analyse de cette page où rien n'est laissé au hasard, et de son évolution, doit nous en apprendre beaucoup sur la stratégie de la firme. Je m'en tiendrai à un rapide survol de la palette des services présentés sur Google.com (ici, attention cette présentation est évolutive dans le temps et selon la situation du terminal d'interrogation), mais une analyse plus approfondie et un repérage des nuances entre les différentes versions nationales seraient aussi à mon avis riches d'enseignements.
Voici donc quelques réflexions sur la partie basse de la page. Je ne ferai pas, cette fois, d'analyse historique.
Remarquons d'abord que le lien vers Chrome a disparu quelques jours seulement après son annonce, ce qui relativise le positionnement de ce nouveau service : service important puisqu'il a eu les honneurs de la page-coeur, mais encore service dilemme. Sa réussite n'est pas assurée.
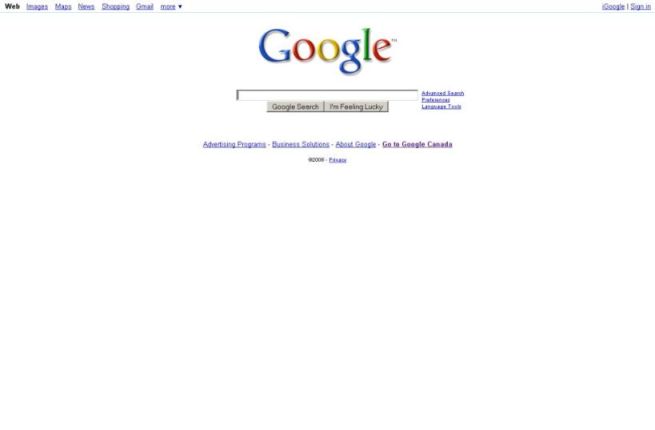
Juste en dessous de la fenêtre, on trouve deux boutons Google Search et I'm feeling lucky. Ces boutons sont présents dès la première page d'interrogation, il y a vingt dix ans (merci Alain ;-)). Ils n'ont ni changé de place, ni de formulation. L'un et l'autre forment le service de base central de Google. L'adjonction de ces deux boutons est essentielle. Elle montre que dès le départ Google ne s'est pas pensé comme un simple service de recherche, mais bien aussi comme un outil de navigation. Il est vraisemblable que l'étude des logs a confirmé très vite Google dans son intuition : nombre d'internautes, de plus en plus l'utilisent directement pour naviguer grâce au second bouton.
Sans avoir accès aux données du moteur, la spectaculaire évolution du regard sur les pages de réponses de Google entre 2005 et 2008 montre assez à quel point la tendance en ce sens est radicale :
“Has Google gotten better?,” Think Eyetracking, Septembre 4, 2008, là.
(Aparté : cette évolution est heureuse pour les bibliothèques. Le créneau de la recherche pertinente sera bientôt libre..)
Je laisse les boutons de droite, destinés à ceux qui souhaitent affiner leurs recherches (mais ils mériteraient bien aussi une analyse), pour conclure mon analyse par la barre du dessous. On y trouve quatre boutons.
Celui de droite me propose d'aller à Google Canada. Ainsi, je suis repéré par la firme comme résident du Canada. Impossible d'y échapper, je suis bien où elle dit que je suis. Il n'est pas anodin que le découpage soit géographique et selon les États. Google est multinationale, pas internationale ou transnationale comme parfois on pourrait le croire. La segmentation de sa cible est d'abord nationale et cette segmentation est radicale, l'internaute ne peut s'y soustraire : même s'il peut choisir d'utiliser les services destinés à d'autres nations, il sera repéré comme issu de sa nation de résidence. Il y a là vraisemblablement une double raison. Tout d'abord, malgré toute la littérature sur la globalisation, l'organisation des marchés est d'abord nationale et les attitudes des consommateurs varient selon les cultures nationales. Ensuite, nous sommes sur le terrain de l'information et, même sans évoquer la censure politique, les règles de droit (propriété intellectuelle, données..) varient suivant les pays. Le Web couvre la planète, mais celle-ci reste une mosaïque de nations, tout particulièrement dans l'information.
Passons le bouton About Google, peu différent de ce que l'on retrouve sur tous les sites corporatifs, pour conclure sur les deux boutons de gauche : Advertising Programs et Business Solutions. Ces deux boutons sont les seuls à vendre quelque chose. Nous sommes d'abord dans un service gratuit qui s'adresse aux internautes pour capter leur attention (tout le reste de la page), néanmoins il s'agit de ce qu'on appelle un marché bi-face et ces deux boutons représentent la seconde face, celle des transactions commerciales.
La concomitance de ces deux boutons est étonnante et trahit l'hésitation de Google sur sa stratégie ou la difficulté de sa diversification. Une première analyse pourrait nous faire conclure que la firme a une stratégie commerciale avec deux volets complémentaires : la vente de publicité d'un côté, la vente de services aux entreprises de l'autre. En cliquant sur les boutons, on retrouve bien sous celui de gauche les propositions Adwords et Adsense de vente de mots et d'espaces publicitaire.. mais sous celui de droite, on retrouve les mêmes services proposés auxquels s'ajoute simplement une troisième offre pour augmenter la productivité de l'entreprise qui consiste à une recherche universelle, un certain nombre d'outils bureautiques partagés ou la publication de cartes personnalisées. Cette troisième offre, on le voit, cherche à diversifier la firme vers la bureautique, mais elle est encore peu structurée et surtout complètement gratuite. Clairement, Google n'a pas encore trouvé comment diversifier ses rentrées financières à 98% issues de la publicité commerciale.
Le contraste est flagrant entre ces hésitations manifestes et l'intuition de départ que nous avons rappelée plus haut. Tout cela relativise les discours souvent sans recul sur cette firme qui reste une firme comme les autres avec une stratégie commerciale ordinaire, des forces certes, mais aussi des faiblesses.
Complément du 23 septembre 2008
Repéré grâce à Olivier (qui le commente ici) un calendrier de l'histoire de la firme réalisé par elle-même pour son 10ème anniversaire, là.
Complément du 8 octobre 2008
Voir ce billet sur l'affichage des résultats sur un téléphone cellulaire :
Olivier Andrieu, “Les moteurs de recherche, avaleurs de trafic ? ,” Abondance, Octobre 8, 2008, ici.
Voir aussi cette excellente vidéo de l'ensemble des Home Pages de Google sur 10 ans, réalisée par OpcionWeb : ici
Celle-ci permet de constater en 4mn que j'ai sans doute été trop partiel dans mon analyse réalisée laborieusement par quelques sondages. En particulier, les annonces en première page comme celle de Chrome ont été beaucoup plus nombreuses que je le croyais.
Complément du 28 octobre 2008
Voir aussi les deux billets de J. Véronis sur dream Orange : Y a-t-il un Web après Google ? ici et là.
Complément du 10 mai 2008
Voir aussi le Journal du Net ici
28-03-2012